
NETFLIX
Введение
Я решила проанализировать данные о фильмах и телешоу, доступных на популярном сервисе потокового вещания Netflix. Данный набор данных можно использовать для поиска названия, типа, режиссера, актерского состава, страны, даты добавления, года выпуска, рейтинга, продолжительности, жанра и описания фильмов и телешоу.
Ссылка: https://www.kaggle.com/datasets/imtkaggleteam/netflix/data
Анализ данных Netflix предоставляет ценную информацию для понимания аудитории, оптимизации стратегии контента и принятия обоснованных решений в индустрии развлечений. Мне бы хотелось проанализировать: - какие жанры (драмы, комедии, боевики и т. д.) и темы (любовь, война, будущее и т. д.) наиболее популярны среди зрителей определенных стран. - какие актеры и режиссеры привлекают наибольшую аудиторию. - как менялись предпочтения аудитории с течением времени (анализ исторических данных)
Для отображения результатов своих исследований я планирую использовать столбчатые и круговые диаграммы, а также диаграммы корреляции в разных цветовых палитрах. Данный вид графики, скорее всего, наиболее точно и красиво визуализирует мой код.
Для начала, сделаем табличку красивой :)
Я буду анализировать только фильмы, поменяю местами столбцы и уберу ненужную мне информацию.

Делаем title перым столбцом в таблице: title = df['title'] df = df.drop ('title', axis=1) df.insert (1, 'title', title)
Делаем release_year третьим столбцом в таблице: release_year = df['release_year'] df = df.drop ('release_year', axis=1) df.insert (3, 'release_year', release_year) Переименовываем release_year в release: df = df.sort_values (by='release_year') df = df.rename (columns={'release_year': 'release'})
Делаем country четвертым столбцом в таблице: country = df['country'] df = df.drop ('country', axis=1) df.insert (4, 'country', country)
Делаем duration пятым столбцом в таблице: duration = df['duration'] df = df.drop ('duration', axis=1) df.insert (5, 'duration', duration)
Делаем date_added шестым столбцом в таблице: date_added = df['date_added'] df = df.drop ('date_added', axis=1) df.insert (6, 'date_added', date_added) Все значения в столбце date_added приводим к виду 00.00.0000 (день.месяц.год): df['date_added'] = pd.to_datetime (df['date_added'], errors='coerce') df['date_added'] = df['date_added'].dt.strftime ('%d.%m.%Y') Переименовываем date_added в added: df = df.sort_values (by='date_added') df = df.rename (columns={'date_added': 'added'})
Фильтруем столбец 'type' и удаляем столбец 'type': df = df[df['type'] == 'Movie'] df = df.drop ('type', axis=1) Переименовываем столбец 'title' в 'Movies' и добавляем кавычки: df = df.rename (columns={'title': 'Movies'}) df['Movies'] = '"' + df['Movies'] + '"'
Убираем колонки show_id и rating: df.drop (['show_id', 'rating'], axis=1)
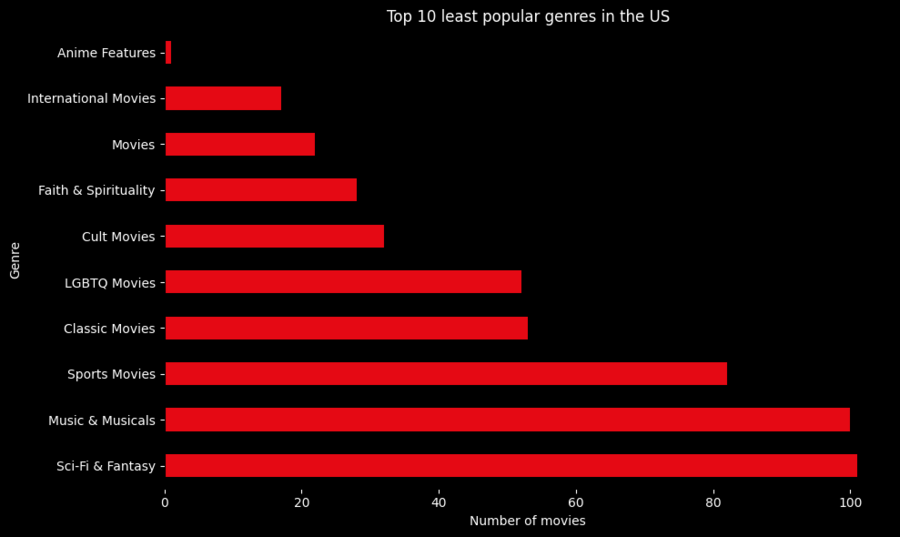
Топ-10 самых непопулярных жанров для США
Фильтрация данных по Соединенным Штатам: united_states_df = df[df['country'] == 'United States']
Разделение жанров и создание списка всех жанров: genres_list = [] for genres in united_states_df['genres'].dropna (): genres_list.extend (genres.split (', '))
Подсчет популярности жанров: genres_counts = pd.Series (genres_list).value_counts ()
Выбор топ-10 наименее популярных жанров: least_popular_genres = genres_counts.nsmallest (10)
Визуализация в виде перевернутой столбчатой диаграммы: plt.rcParams['figure.facecolor'] = 'black' plt.rcParams['axes.facecolor'] = 'black' plt.rcParams['text.color'] = 'white' plt.rcParams['xtick.color'] = 'white' plt.rcParams['ytick.color'] = 'white' plt.rcParams['axes.labelcolor'] = 'white' plt.rcParams['axes.titlecolor'] = 'white' plt.figure (figsize=(10, 6)) least_popular_genres.plot (kind='barh', color='#E50914') plt.gca ().invert_yaxis ()
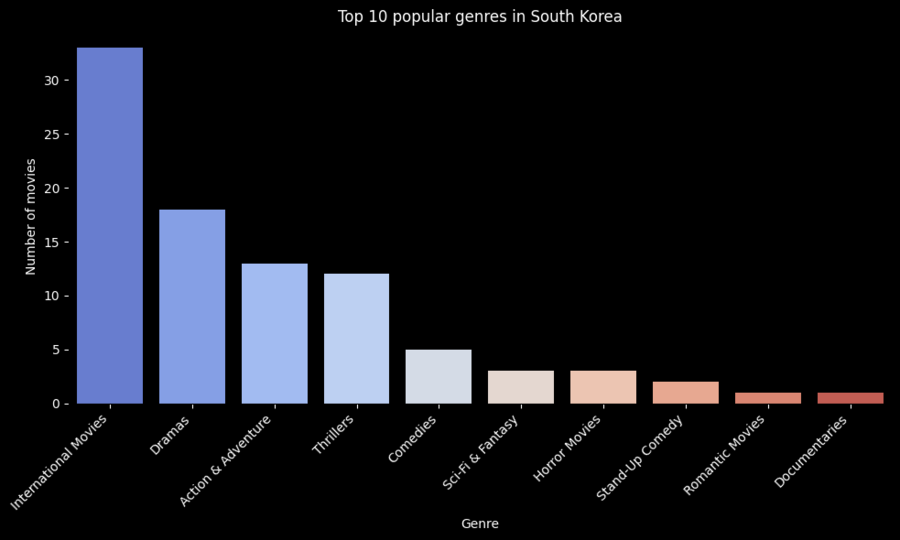
Топ-10 самых популярных жанров для Южной Кореи
Фильтрация данных по Южной Корее: south_korea_df = df[df['country'] == 'South Korea']
Разделение жанров и создание списка всех жанров: genres_list = [] for genres in south_korea_df['genres'].dropna (): genres_list.extend (genres.split (', '))
Подсчет популярности жанров: genres_counts = pd.Series (genres_list).value_counts ()
Выбор топ-10 жанров: top_10_genres = genres_counts.head (10)
Построение столбчатой диаграммы: plt.rcParams['figure.facecolor'] = 'black' plt.rcParams['axes.facecolor'] = 'black' plt.rcParams['text.color'] = 'white' plt.rcParams['xtick.color'] = 'white' plt.rcParams['ytick.color'] = 'white' plt.rcParams['axes.labelcolor'] = 'white' plt.rcParams['axes.titlecolor'] = 'white' plt.figure (figsize=(10, 6)) sns.barplot (x=top_10_genres.index, y=top_10_genres.values, palette="coolwarm») plt.xlabel («Genre») plt.ylabel («Number of movies») plt.title («Top 10 popular genres in South Korea») plt.xticks (rotation=45, ha="right») plt.tight_layout () plt.show ()
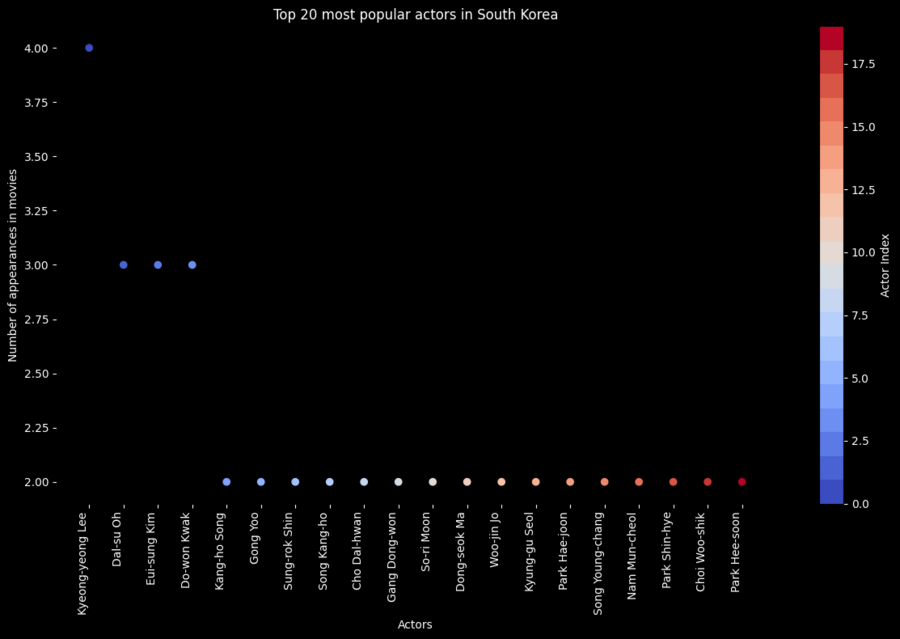
Топ-20 самых популярных актеров Южной Кореи
Фильтрация данных по Южной Корее: korea_df = df[df['country'] == 'South Korea'].copy ()
Проверяем, есть ли данные по Южной Корее: if korea_df.empty: print («Нет данных для Южной Кореи.») exit ()
Обработка столбца с актерами: actors_list = [] for actors in korea_df['cast'].dropna (): actors_list.extend (actors.split (', '))
Подсчет частоты появления каждого актера: from collections import Counter actors_counts = Counter (actors_list)
Выбор топ-20 актеров: top_20_actors = actors_counts.most_common (20)
Создание DataFrame для визуализации: top_actors_df = pd.DataFrame (top_20_actors, columns=['actor', 'count'])
Визуализация: plt.rcParams['figure.facecolor'] = 'black' plt.rcParams['axes.facecolor'] = 'black' plt.rcParams['text.color'] = 'white' plt.rcParams['xtick.color'] = 'white' plt.rcParams['ytick.color'] = 'white' plt.rcParams['axes.labelcolor'] = 'white' осей plt.rcParams['axes.titlecolor'] = 'white' colors = plt.cm.get_cmap ('coolwarm', len (top_actors_df)) plt.figure (figsize=(12, 8)) plt.scatter (top_actors_df.index, top_actors_df['count'], c=top_actors_df.index, cmap=colors) plt.xlabel («Actors») plt.ylabel («Number of appearances in movies») plt.title («Top 20 most popular actors in South Korea») plt.colorbar (label="Actor Index») plt.xticks (top_actors_df.index, top_actors_df['actor'], rotation=90, ha="right») plt.tight_layout () plt.show ()
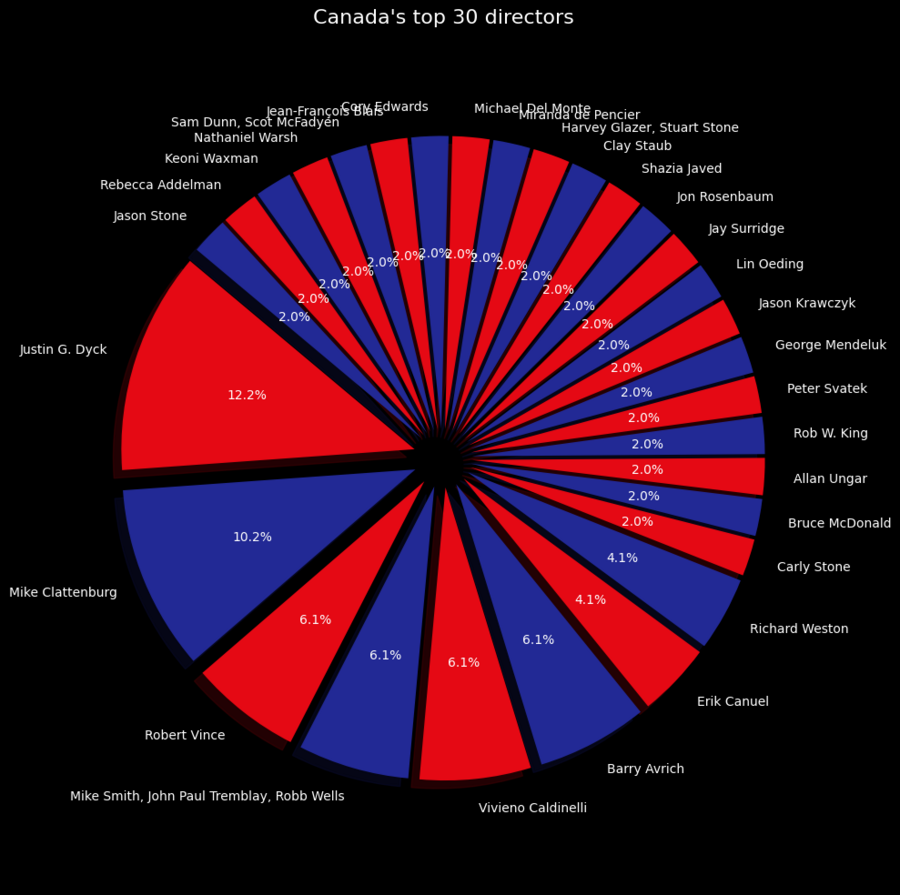
Топ-30 режиссеров Канады
Фильтрация данных для Канады: canada_df = df[df['country'] == 'Canada']
Подсчет количества фильмов/шоу для каждого режиссера: director_counts = canada_df['director'].value_counts ()
Выбор 30 самых популярных режиссеров: top_30_directors = director_counts.head (30)
Подготовка данных для круговой диаграммы: labels = top_30_directors.index sizes = top_30_directors.values colors = ['#FFFF00', '#800080'] * 15 explode = [0.1] * 30
Создание круговой диаграммы: plt.rcParams['figure.facecolor'] = 'black' plt.rcParams['axes.facecolor'] = 'black' plt.rcParams['text.color'] = 'white' plt.rcParams['xtick.color'] = 'white' plt.rcParams['ytick.color'] = 'white' plt.rcParams['axes.labelcolor'] = 'white' plt.rcParams['axes.titlecolor'] = 'white' plt.figure (figsize=(10, 10)) plt.pie (sizes, explode=explode, labels=labels, colors=colors, autopct='%1.1f%%', shadow=True, startangle=140, textprops={'fontsize': 10}) plt.title («Canada’s top 30 directors», fontsize=16) plt.axis ('equal') plt.tight_layout () plt.show ()
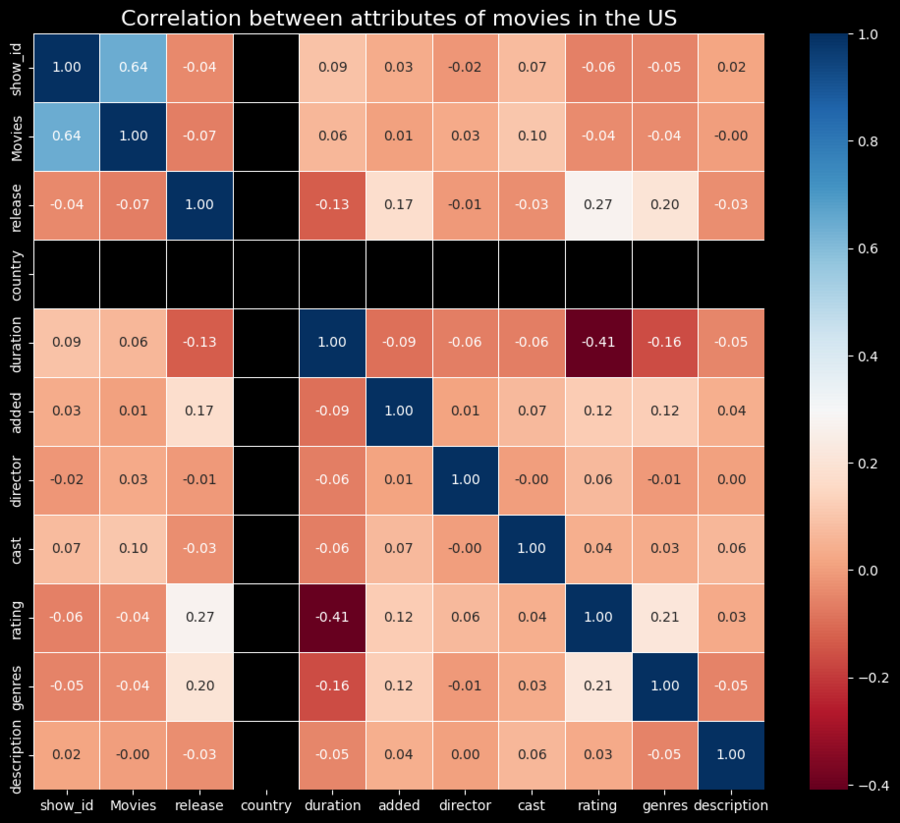
Корреляция между признаками фильмов в США
from sklearn.preprocessing import LabelEncoder
Фильтруем по стране (США): df_usa = df[df['country'] == 'United States']
Преобразование категориальных признаков в числовые: categorical_cols = df_usa.select_dtypes (include='object').columns
le = LabelEncoder () for col in categorical_cols: df_usa[col] = le.fit_transform (df_usa[col].astype (str))
Анализ корреляции: correlation_matrix = df_usa.corr (numeric_only=True)
Визуализация корреляции: plt.rcParams['figure.facecolor'] = 'black' plt.rcParams['axes.facecolor'] = 'black' plt.rcParams['text.color'] = 'white' plt.rcParams['xtick.color'] = 'white' plt.rcParams['ytick.color'] = 'white' plt.rcParams['axes.labelcolor'] = 'white' plt.rcParams['axes.titlecolor'] = 'white' plt.figure (figsize=(12, 10)) sns.heatmap (correlation_matrix, annot=True, cmap='RdBu', fmt=».2f», linewidths=.5) plt.title ('Correlation between attributes of movies in the US', fontsize=16) plt.show ()
Для генерации частей кода я использовала нейросеть https://chatgptchatapp.com/
Я старалась придерживаться цветовой палитры заставки Netflix (красный, синий определенных оттенков).
Итоговые графики
Блокнот
Ссылка на Яндекс Диск: https://disk.yandex.ru/d/0lyJ-Khx7u6Ziw
Ссылка на Google Colab: https://colab.research.google.com/drive/1EU_LSv47St7XeY9sinonwiX4clMWm65Z?usp=sharing



