
Training of a generic neurostudent to the art style of Yoshitomo Nara
Ideas description
My goal was to teach a generic neurosmart to paint in the style of Yoshitomo Nara, a Japanese artist whose work is clinging to his emotion and simplicity. His characters with big eyes and hidden rebel energy are something special, and I wanted to see if I could get neurosmart into this atmosphere.
Dataset collection
To begin with, I collected a dataset of 125 pictures of Nar’s work, mostly of his typical characters with big eyes and pastoral background. All the images I pre-processed — I did a cut to square format, which made it possible to create a quality dataset for model learning.

Learning process
I downloaded all the images from Google Colab, where I was trained. Using Stable Diffusion XL as a base, and adding Dreambooth to the LoRA adaptation method for further training, it helped save resources and make the process faster.
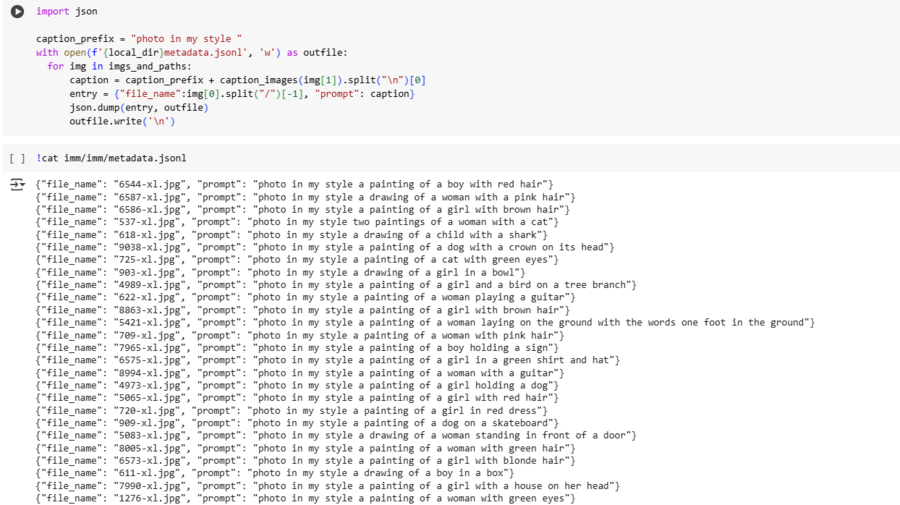
Descriptions to the dataset for model learning
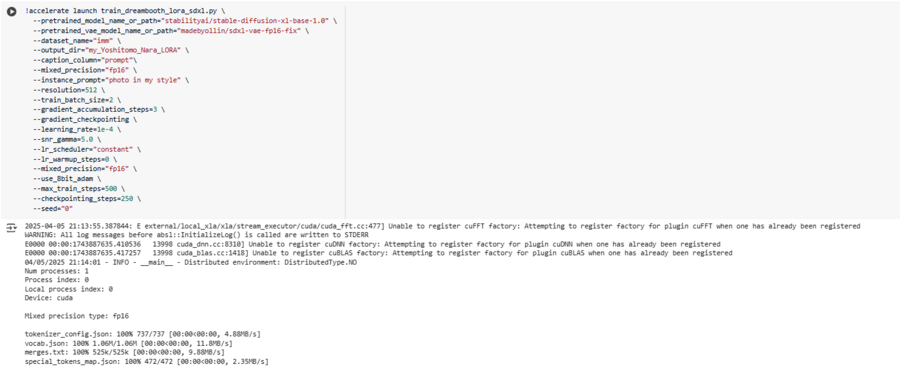
Process of training the model on images and their descriptions
Sample image generation using a trained model
Results and analysis
The trained model successfully generates images that show the characteristic elements of the Yoshitomo Nara style: big expression eyes, soft colors, and light pencil texture.


prompt = «photo in my style A lone child with oversized, expressive eyes and a hint of mischif»


Prompt = «Photo in my style innocent yet rebellios figure with a slight smirk, set against a minimum, pastel background»
I tried to generate a «cute character with a flower» and «animal with human features» — and it was great. True, sometimes the hands or small parts were crooked, but the style was generally guessed at once. I also ran tests with a different number of generation steps (from 25 to 95) — the 50 to 75 steps were the clearest result.


prompt = «photo in my style cute, childlike character holding a flower, evoking both vulnerability and defiant energy»


prompt = «photo in my style stylized animal with human-like features and a playful yet enigmatic expression, in a simple color palette»
prompt = «photo in my style stylized animal with human-like features and a playful yet enigmatic expression, in a simple color palette»


prompt = «photo in my style solitary figure in a whimsical, minimalist scene, blending innocence with a touch of rebellious spirit»
prompt = «photo in my style solitary figure in a whimsical, minimalist scene, blending innocence with a touch of rebellious spirit»
prompt = «photo in my style a painting of a girl and boy with oversized eyes and a hint of mischif»


Prompt = «Photo in my style a painting of a car»
I also tried to generate images by the descriptions that were created automatically and compare them to the original images.


Prompt = «Photo in my style cute, childlike cardacter holding a flyer, evoking another vulnerability and defiant energy»
To improve the generation, I tried to add a little bit to the prompt and to increase the number of generation steps, which has improved the quality.
Prompt = «Photo in my style a painting of a cat with green eyes»


1-prompt = «Photo in my style a painting of a cat with green eyes and human like face»
Conclusions
The results made me happy, and the neurosmart caught the essence of Nar’s style: simplicity, emotion, and that very rebel vibe. But there’s a place to grow. For example, if I had more pictures on the dataset, little mistakes like weird hands could disappear. I also noticed that the model worked better with characters than with the environment — cars, for example, didn’t come out as detailed.
Description of the application of the generic model
https://chat.qwen.ai/ was used to generate more complex prompts and optimize the code
Code and date network: https://drive.google.com/drive/u/0/folders/1s-wEH9moKJv5fwkoAA8hSN-BC4xCziq



